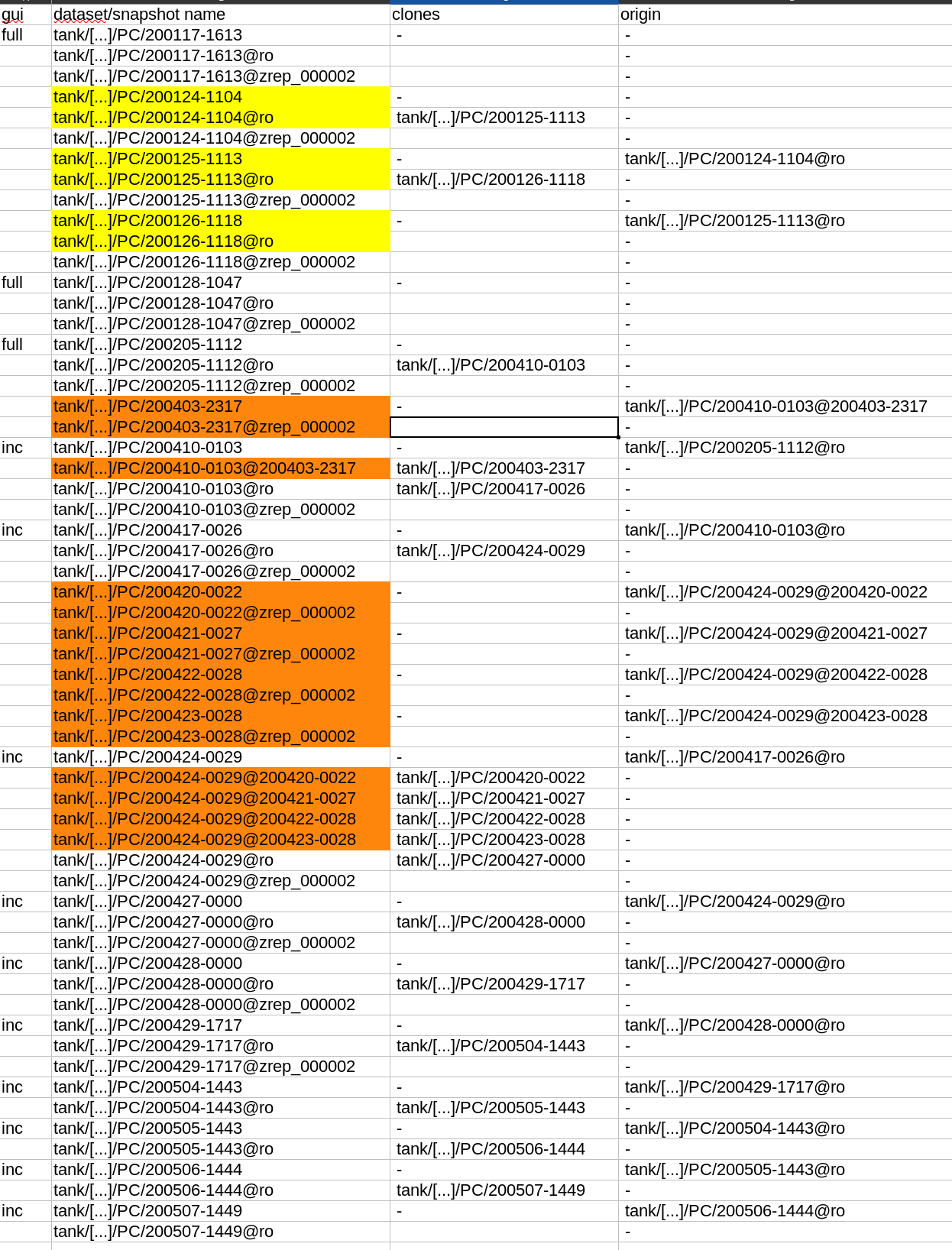
I started replicating our backup server, which is using zfs storage and the incremental-forever style backups, to another server using the zrepl tool. Since zrepl creates its own snapshots to to incremental replication, when urbackup deletes a backup orphan datasets are left behind. I was going to write a script to clean up these deleted datasets, but I can’t wrap my head around what I’m seeing. Below screenshot is the output of zfs list -t filesystem,snapshot -r -o names,clones,origin tank/[...]/PC. The leftmost column indicates which backups are shown in the webinterface and wether they are full or incremental backups.
The cells marked in yellow belong to an incremental backup chain that contains no backups that are shown in the gui. I don’t understand why they still exist. Since the @ro snapshot is still there, I think the server hasn’t even tried deleting them. According to my retention settings they should have been deleted for a long time. Are these safe to destroy?
The cells marked in orange show backups that were deleted by the server after the zrep snapshot was created. How can I reliably determine wether it is safe to delete these volumes (including the zrep snapshot) so the deletion can be propagated to the mirror system? Is the absence of an @ro snapshot a safe indicator? Or do I need to lookup from the sqlite database?
Can someone explain to me how the snapshot promotion during the cleanup works? I don’t understand how a snapshot of a newer dataset (like 200410-0103@200403-2317) can be the parent of an older dataset (like 200403-2317).
Thanks for any help.
@Jeeves can you help maybe? You mentioned a long time ago that thanks to zfs send/receive we can replicate easily, but I can’t figure out how to actually use it in production without ending up with a full pool.
To be fair, it’s less easy than I anticipated when I asked for implementation.
So, what urbackup does is creating a snapshot of the latest backup, and then clone that snapshot to a working filesystem. zfs send|receive did not work for me. At least, not as I am doing it normally.
The leftover snapshots are usually by error, because they are dependent on some other filesystems. I regularly need to promote filesystems, making them independent from the snapshots that should be removed.
Sorry but that is too superficial to help me. I know how to administer zfs. What I don’t know is which volumes are referenced by urbackup and which are remnants of failed deletes.
That would be logical and easy to grasp. But as in my question #3, it seems to do more than that.
When the snapshots marked in yellow should have been deleted, there was no zrep snapshot yet, so no dependent filesystems that would prevent a delete. So the only explanation is a bug in urbackup.
The lack of removing snapshots is some error in Urbackup. I compared the backups in the database and on the filesystem a few times, and was able to remove the backups that should not be on disk. Sometimes, I needed to promote a newer backup, which was depending on a backup that needed to be removed.
The system is not as bugfree as I would like, but it hasn’t bothered me enough yet to dive into it and bug @uroni about it, sorry.
I thought about trying those changes, but they require updating for the current zfs version. And to do that, I need to understand what snapshot hierarchy urbackup is expecting, specifically Question #3.
It’s build for btrfs, so it is a bit awkward with ZFS. When creating a backup it creates a volume, then writes to it, then makes it “read-only” – in ZFS by creating a “@ro” snapshot. On incremental backup it clones the “@ro” snapshot then writes to that one, then creates a new “@ro” snapshot of the new backup.
On removal it promotes, deletes and renames stuff until the snapshot+volume can be deleted…
@uroni I’m an OpenZFS developer. I’m new to urbackup. We are investigating it for use at my day job.
Without ZFS, urbackup seems to have:
A directory per client.
Inside (1), a directory per backup.
Inside (1), a symlink named current pointing to (2) of the last successful backup.
For example, we have:
$ ls “/srv/backup/Win 10 Pro Test (5)”
201105-2306 current
(If that is a date-based backup name, then we must have the clock way wrong somewhere.)
With ZFS, I would have expected something like:
A dataset per client, mounted at the client directory. For example, if tank/backup is mounted at /srv/backup, the dataset would be tank/backup/Win 10 Pro Test (5) mounted at /srv/backup/Win 10 Pro Test (5)
urbackup writes the backup data into that dataset.
When the backup completes, take a snapshot, e.g. tank/backup/Win 10 Pro Test (5)@201105-2306
There is no need for a current symlink, as the current backup can be easily identified: it is always the latest snapshot. The previous backup can be read by accessing e.g. /srv/backup/Win 10 Pro Test (5)/.zfs/snapshot/201105-2306. This will be automounted when you chdir() into it. Note that the .zfs directory is not normally visible. That is, it won’t show up in readdir() at all. If you’re poking around from the command line, you can just do cd .zfs anyway, and that works. (This can be changed with zfs set snapdir=visible, but there is usually no need to do that.)
This seems like it would be a lot simpler. There would be one dataset per client, not multiple clones. Removing an old backup is just: zfs destroy tank/backup/Win 10 Pro Test (5)@201105-2306 Multiple snapshots can be destroyed with one command (subject to OS command line length limits): zfs destroy tank/backup/Win 10 Pro Test (5)@201105-2306,201106-2300
I know this kinda old but I think what @rlaager describes is still relevant. I am looking into using Urbackup with ZFS as well and expected the same setup as @rlaager describes.
@uroni Is this currently possible or has this been discussed outside of this forum (Github?). I would be interested in the implementation as described above.
This would be great and solve some problems we have with using urbackup.
I can also understand the reason it was done the way it’s done, since I assume the server can use the same code locating and browsing backups now, no matter if the underlying FS is ZFS, BTRFS, Ext 4 or UFS.
But this would be a huge feature, but probably a big change in the code