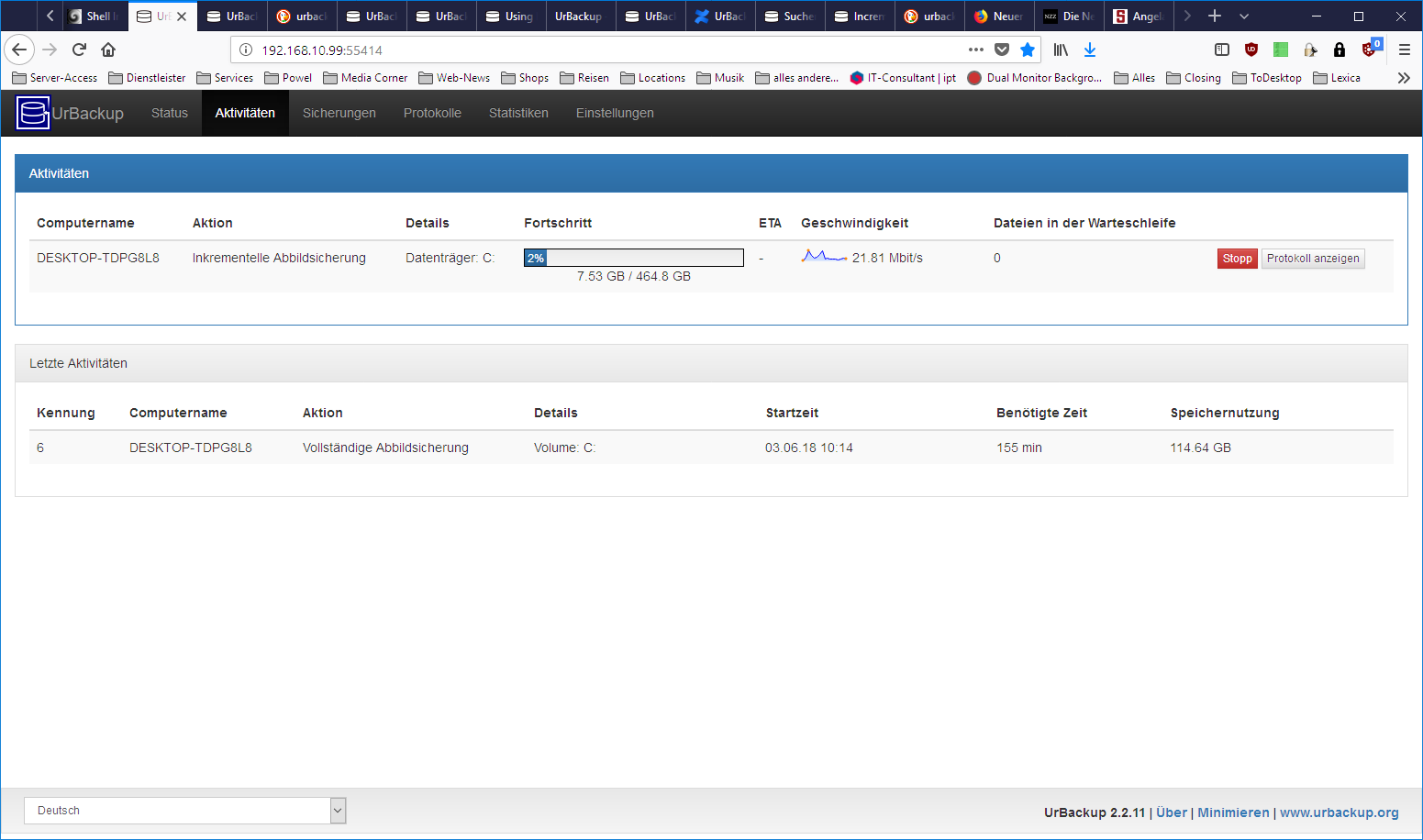
Incremental image backups are too big to really be incrementals.
Am I doing something wrong?
Hi MrBates,
I have the same view under my “Activities” where it shows a big incremental image size; However, when the incremental backup is done check its actual used disk space under backups/client and you will notice its few gigabytes.
Sam
Hi zzzviper,
Thanks for your reply!
Yes, it’s true it displays more than what’s actually being transferred, but the thing is that I still feel that what’s being transferred is more than needed.
Let’s say I just finished an incremental image backup and I immediately run another one, still many gigabytes will be transferred, yet not so much has changed on the disk.
It is my understanding that the page file and swap file are being skipped by urbackup, so there’s really no explanation for the amount of data being transferred.
I had a thought that might be completely off, but worth a try. Is it possible that each sector is being hashed, and the hash is being transferred? That way even if no file has changed since the previous backup, still all the hashes have to be sent to the server, and on a slow internet connection it still takes hours if not days.
If this is the case, I have an idea that might optimize this process. Instead of only hashing each sector individually, also hash a group of adjacent sectors, and pass that to the server. Only if the group hash differs, dive deeper into individual sector hashes. In most cases sectors don’t change, so the speed improvement will be significant.
For example: hash 1 sector, 100 sectors and 1000 sectors. On a 200GB partition, it means only 50 hashes have to be transferred to the server instead of 50,000 hashes.
True, it will impose more stress on the CPU, so it can be introduced as an option, that will default to ON only if the backup is done over an internet connection, and the admin can always turn it off.
Makes sense?
Can someone please address this issue?
It doesn’t make sense that incremental image backups take almost an entire day to finish, while consuming my limited outgoing internet bandwidth.
Is there a way to identify which files have changed since the last backup? This could help identify if it’s a bug or not.
@MrBates just reading the documentation about this, your Incremental Images are going to be “big” and take a long time without Change Block Tracking.
You can purchase CBT from here which likely would address the situation you’re experiencing.
Thanks @Jarli10 for your reply.
I have no problem purchasing this addon, but from its description it won’t help me.
It prevents reading the entire disk in pursue of changed blocks, with which I have no problem.
My problem is with transferred data, which seems to be bigger than necessary.
Thanks!
Change block tracking for UrBackup Client on Windows 2.x
Change block tracking for UrBackup Client on Windows speeds up image and file backups performed by UrBackup by tracking which blocks change between backups. Without change block tracking all data has to be read and inspected in order to find and transfer the differences during an incremental image or file backup. This can take hours compared to the same taking minutes with change block information. This enables backup strategies with hourly (or less) incremental image backups and speeds up incremental file backups with large files (e.g. virtual disks).
Based on the description of what you are seeing, my guess is you need CBT. Is this a Windows system?
Maybe the exclusion is not working. You could run the client in debug logging mode and look for Trying to exclude contents of file lines and see if all the expected files are excluded
pagefile.sys, \System Volume Information\*{3808876b-c176-4e48-b7ae-04046e6cc752}*
Thanks for the reply.
How do I run the client in debug mode?
I changed the warn to debug in C:\Program Files\UrBackup\args.txt and restarted the client, but didn’t see any logs prefixed with “debug”.
Maybe it’s because it’s in the middle of an image backup?
Should I stop the ongoing backup and start a new one for the change to take effect?
How do I run the client in debug mode?
Hi
There s a bat script to enable debug mode.
I have the same going on. My SSD has 464GB. My first full image backup had 114.64GB. The following incremental image backup wants to transfer 464GB. The complete disk…
Without CBT it cannot show an estimate on how much is going to be transferred at the beginning of the backup.
You should wait for the backup to finish and then complain if that size is too large.
Understood. I still think there is something fishy…because I have done the first full backup 2 day ago and I doubt that 52GB of files have changed since then. But when I stopped the backup process, 52GB have already been transfered. And 52GB were not the end…
Do I have to transfer all 464GB and the server rejects what he doesn’t need or will the client only transfer what is needed?
Hi Mike, when i run my image backups I also see it passing by every byte on the server on the progress bar, but from what I see on my backup drive, hardly anything is being transferred and saved.
It just reads over the whole drive looking for changes, all 464 GB in your case, but doesn’t actually transfer 464 GB (or at least it doesn’t in my case). The only change block tracking adds is that it doesn’t have to scan every single byte on the disk and compare it to the data on the backup server for changes, which speeds up my backups significantly.
Alright. While the incremental image backup is running, I see around 100Mbits beeing transfered. This puts up a few more questions from my side:
Thank you for clarifications!
From the documentation, Urbackup transfers everything appropriate the particular backup type that is being run (whether it’s a file or image backup, and whether it’s full or incremental) to the server. The server then does comparison checks server side to reduce the amount of CPU load on the client. Yes everything is temporarily stored on the backup server, but is removed and is then either hard or soft linked rather than keeping another copy.
If you’re concerned about drive integrity, you really should look into using actual surveillance drives (Western Digital Purple) that are designed for prolonged read/write operations that backup servers encounter (if you have the funds, I’d just go straight to enterprise drives and be done with it though). Also consider using a RAID setup just in case of drive failure. Even if yours is a home set-up, a small NAS box will go a long way to
Just for clarification, we pull 200TB daily through our network to the backup server and I’m using a mix of surveillance and enterprise drives with 1 drive failure in 4 years on a 1PB RAID 10 setup. Load on the clients is negligible, usually around 5% CPU peak. Server however takes the brunt of the work, usually peaking at 99% CPU on all 64 cores (but surprisingly bugger all RAM, which I thought would have been a requirement). Network load is throttled to 600Mbits and doesn’t disrupt the natural flow.
Hi Mike,
Just to add to BauM’s response. The server and client do hashing and comparing and yes the server does most of the work. Howerver, in my experience not all the data is send to the server, perhaps all the hashes that the client generates for the data on the disks is send to the server, but not all the data. One of my UrBackup servers is on a offsite location with only a 100 Mbit connection to the clients which limits the speed to about 10-11 Mb/sec. One of my servers has a 200 GB disk and while it appears to check all data it only copies about 10 Gb in a incremental backup. This takes about 46 minutes. With 180 GB out of the 200 GB in use on the disk, that would mean the client is sending data to the server at a rate of about 66 Mb/sec. Which is 6 times as fast as the link allows and thus not possible. Keep in mind i’m not accounting for data compression or the overhead of data encryption, which I have active on my backups. So if anyone has evidence to the contrary, please correct me!
So no, I don’t think every byte of data is send from the client to the server and the server only saves what it needs. I believe the client hashes everything, and the hashes are send over and compared on the server, but that can’t be much data given my 100 Mbit/sec speed case that I mentioned above. Based on the evidence, and not going in the source code to confirm. At best in my case above the server only has 31 minutes to transfer data, since it needs 11 out of the 46 minutes to copy the 10 GB of changes over. At 11 Mb/sec, that means it can only transfer over an additional 20.4 GB. But given that i run multiple backups at the same time, without impacting the time it takes this incremental image backup from above, i’d say the actual transferred data in a incremental backup is just the changed data that actually needs to be stored, and perhaps some extra data for the hashes, which i doubt is Gb’s of data, more like Mb/s of data.
So in my experience, No it doesn’t send over everyting to the server, not by a very very long shot.