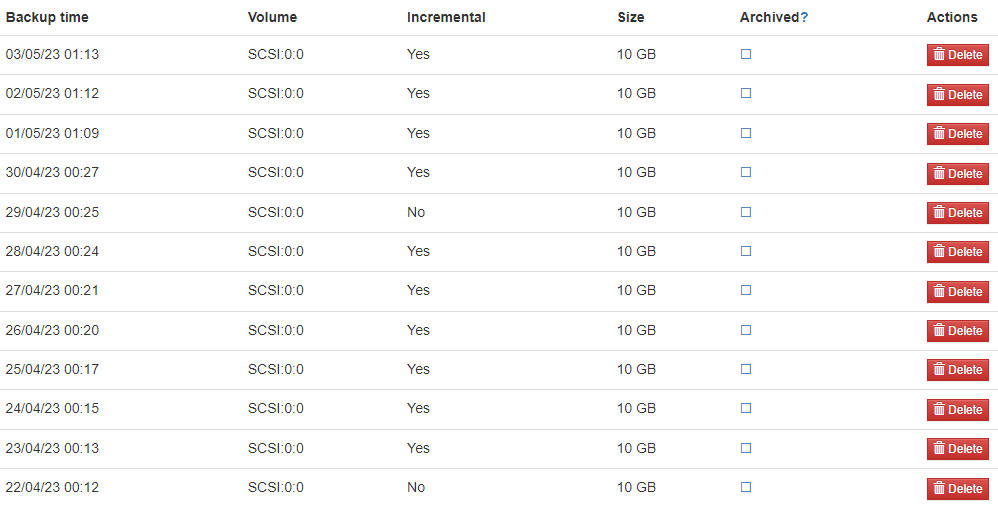
I have set up image backups of two Hyper-V VMs (both are Linux), using the trial version of the Hyper-V client, yet I see in the GUI that all the backups are the same size for both full and incrementals:
I’m still seeing this behaviour and getting concerned by the fact that a backup of a small 60GB server after a few weeks is seemingly now occupying 2TB of backup storage.
You don’t mention more than the server is running on windows. If the backup storage is on ntfs, I don’t think you can use incremental backups that way, but I could be wrong.
I might be wrong, but isn’t that exactly what you are trying to achieve?
When enabled, Data Deduplication optimizes free space on a volume by examining the data on the volume by looking for duplicated portions on the volume Data Deduplication Overview | Microsoft Learn
edit. deduplication works on ntfs too, I was wrong.
Thank-you for the explanation, just a shame Windows itself doesn’t make this clearer - I’m not worried about compression just as long as the reflinks are working as expected.