The bug appears in this configuration:
Client 2.4.11 on Windows 10 x64 (last updates installed)
Server 2.4.14 on Debian 9 (last updates installed)
Looks like some changes were made to the code earlier, but they still don’t work (I reported the bug a year ago).
Files with incorrect names are not visible by network access (if the backup folder shared using Samba).
In Midnight Commander, the filename displayed will contain a diamond with a question mark inside. The program hints that one UTF-8 character is corrupted.
Criticality of the bug: I think “high”. This makes it impossible to completely copy the archive over the network to another computer. Files with corrupted names will not be copied.
It will definitely be a very bad surprise.
Have you considered testing using Debian stable for the server?
I suspect there have been changes and improvements to SAMBA between oldoldstable (9) and stable (11).
Might be nothing to do with your problem, but worth testing.
Haven’t tried the new stable version of Debian. In any case, the incorrect unicode character in the names of the backed up files comes from Urbackup. It is necessary to fight with the root cause, not the consequence.
This wizard upgrades legacy system locales to their UTF-8 equivalent. It also informs users whenever files in their home directory still utilize legacy encodings.
Available in Stretch.
It’s solved the problem for people in the cases where I searched that specific error.
UPDATE:
I compiled the program (2.4.14) with this fix manually added. This code doesn’t work. It looks like that’s why it was not added to the release…
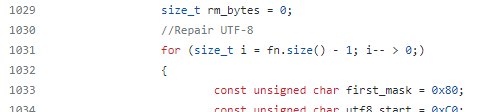
Some time ago the problem with a broken character when shortening long filenames was solved. Now the problem appears again:
Such files become inaccessible both via SMB and locally from the folder where all backups are stored.
Shortening the names of long files during backup does not work correctly. And such files are often found, since the filenames typed in non-Latin characters take up two bytes! The allowed length of a filename in Linux is reduced by about half
Can the error found be corrected? It interferes a lot when working with the backup directory via SAMBA. But this is the easiest way to find the desired file in the backup
Of course, such a file is not copied either via SAMBA or locally via cp or Midnight Commander. You can download the file in the web interface, but its size will always be zero bytes.
Thus, we can say that this file is missing from the backup!
Here is another example to get developers’ attention. I created a file with a name length of 256 bytes. Here is what happened in the UrBackup web interface: