As far as I can tell from studying the forum, it seems that there is no clear picture what is done during an incremental respectively full file backup.
Therefore, before I go on to my question, I want clarify this with my current understanding - correct me if I am wrong.
Most of the confusion comes from the fact, that most of us have the following concept in mind: The data stored during an incremental backup is ‘some kind of information which describes how to get to the current backup state from the previous one’. The consequence of this concept is, that restoring data requires not only the last incremental backup, but all increments since the last full backup.
Now when looking at the manual[1], we can see that this concept does not apply to UrBackup. The term ‘incremental’ is used in the context of file transfer, which means that only files which have changed since the last backup are actually transfered to the server. However, since the server also has knowledge about the full content of the other - not transferred - files(from previous backups - full or incremental), it can use this files to recreate kind of a full backup for the current point in time. The primitive way would be to copy them from a previous backup, but since UrBackup is smart it uses hard-links which accomplish nearly the same, without using storage space twice.
Looking at the manual, it seems that there is no difference between a full and an incremental backup from the point of view how data is stored. The only difference is that during a full backup the full set of data is transferred. If for some reason, files have not been selected for transfer during an incremental backup, the full backup will make sure, that the server really has the current state of the client.
Now we come closer to my question.
The manual claims, that it uses this kind of ‘hard-link’ file level deduplication for all files transferred which is described in the following paragraph:
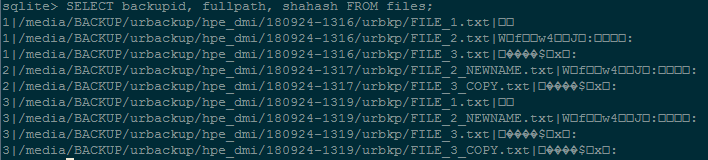
The server downloads the file into a temporary file. This temporary file is either in the urbackup_tmp_files folder in the backup storage dir, or, if you enabled it in the advanced settings, in the temporary folder. On successfully downloading a file the server calculates its hash and looks if there is another file with the same hash value. If such a file exists they are assumed to be the same and a hard link to the other file is saved and the temporary file deleted. If no such file exists the file is moved to the new backup location. File path and hash value are saved into the server database.
This paragraph pretty much sums up, what I have tried to explain in a less algorithmic approach in the beginning.
However - from my testing, this is not true. At least it does not apply to such a broad scope as stated.
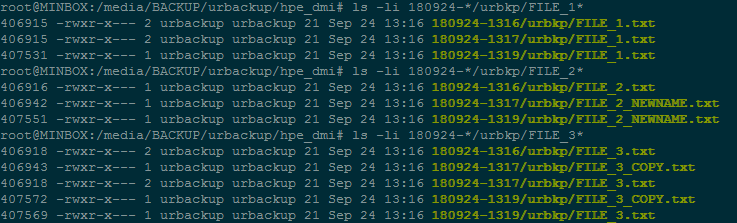
Scenario 1)
I copy/duplicate a file on the client - now having FILE and FILE_COPY, both with the same hash. Doing an incremental backup, this file gets transferred. In accordance to the manual I would expect, that FILE and FILE_COPY hard-link to the same file. This is not true, FILE_COPY is an actual copy also on the server.
A closer look at FILE_COPY and FILE, reveals that this files differ by file attributes(e.g. last modified date). The manual, however, only mentions the hash as a consideration for deduplication.
Scenario 2)
I do two subsequent full backups. Each time all my files have to be retransferred to the server as expected. However, it seems that in this case there is no deduplication at all. No hard-links are created, but all files are saved anew. I can verify this by looking at the inodes.
It seems like a full backup is kind of a full reset, It stops the propagation of silently corrupted files on the server. But with two full backups, I also have two files with the same hash - which opens further questions(future hard-linking, cross client deduplication) which I do not want to elaborate at this point.
So my question is. Is this expected behavior? And if yes - is this documented somewhere in detail?
[1] https://www.urbackup.org/administration_manual.html#x1-280006.1