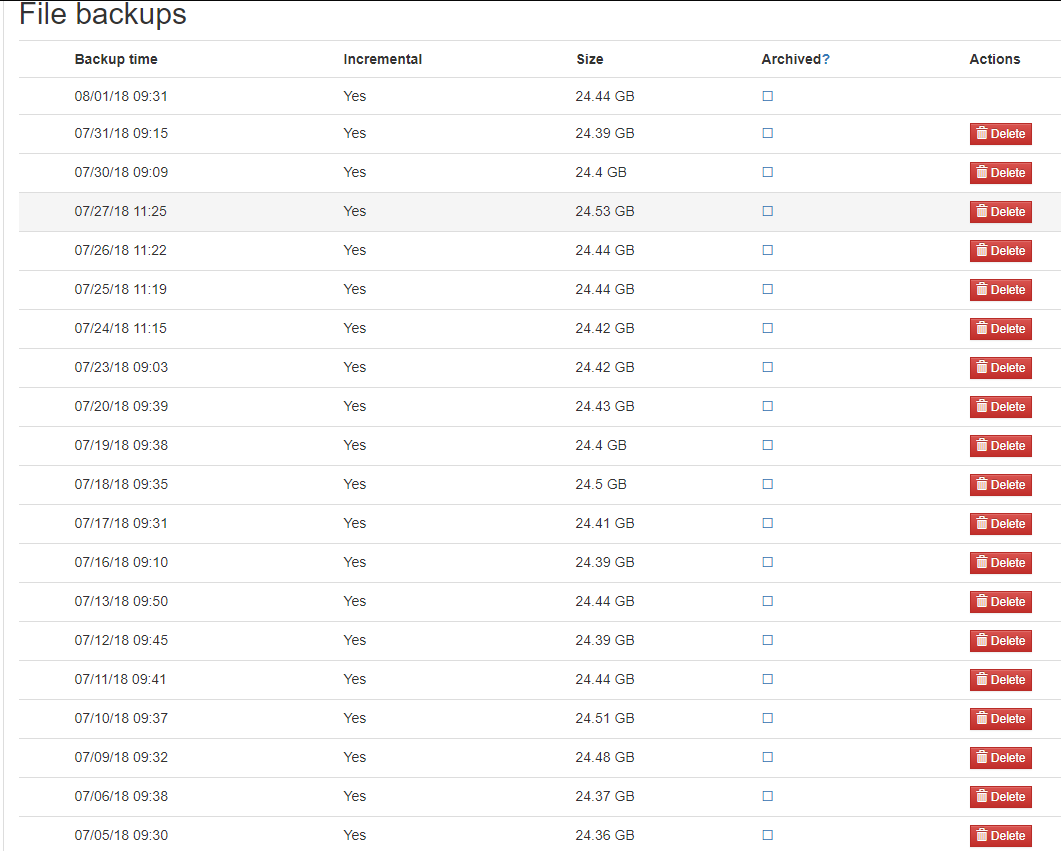
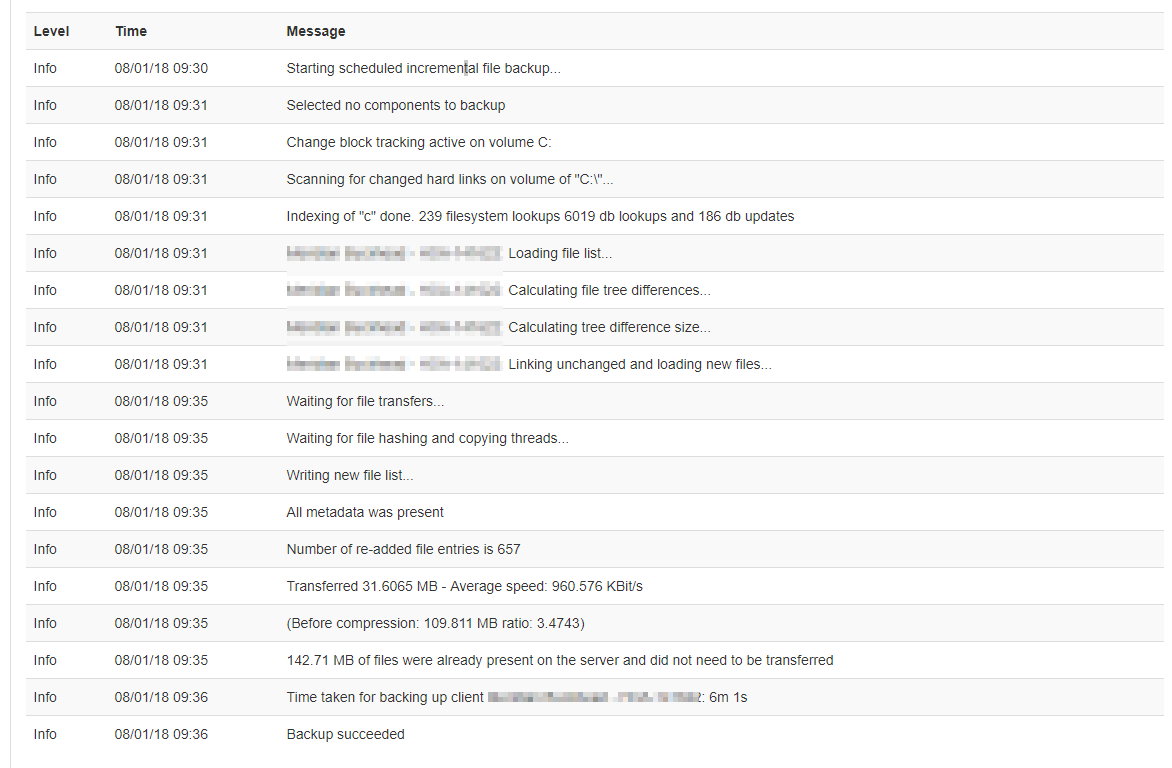
Was looking at top usage backups, and found one that doesn’t make any sense. Looking at daily incremental backup size says it’s incrementing by almost the same size every day
What am I missing here? It’s happening on two different PC’s for the same user (which I migrated their data from old to new PC). I can only guess there’s something unique about the data in their backup? What’s the best way to find the problem?
Is there a recommended method/howto of doing that? I’m guessing you’re talking about doing that on the Urbackup server at the file level? Drilling into folders? du ?
They’re not sparse files. Even though the data isn’t transferred (internet backup clients / block based), it looks like the server re-creates new files, even if only 1-2 blocks are part of the backup.
Unfortunately, this is a drawback of file-based backups. Any tiny change in a file can result in big changes in the backup size due to the need to save a new version of the complete file for each incremental backup.
I had the same issue as you (data transferred was very small, yet backup size was significantly larger), and I tracked most of it to things like log files. My workaround was to exclude these types of files from the backups. That may be hard to do in your case, as PST and VHD files are likely something important.
Regarding your question about determining the space taken up on disk: Yes, the du utility is the right one to use in Linux for this purpose.
You can have a look at the doc and search for the btrfs based storage.
Cons :
Its slightly annoying to setup
You can t reuse/migrate your previous backups
You won’t have inter files deduplication
Pros:
You should get what basically amount to block based de-duplication for the same file via reflink (modifying 1KB in a 1GB file should occupy 1 additional KB)
So you still use the hash database that go along the files; as you do for sym/hardllink storage?
Then you reflink a file if it has the same hash, even if 2 files in the same backup were not originally ref-linked?
Still it has the restriction that the dedup won’t work between clients (except for transfert) ?